A key-value store, also referred to as a key-value database, is a non-relational database.
Each unique identifier is stored as a key with its associated value. This data pairing is known as a “key-value” pair.
In a key-value pair:
- Key
- must be unique
- value associated with the key can be accessed through the key
- can be a plain-text or hashed value
- Value
- can be:
- string
- lists
- objects
- treated as an opaque object
- can be:
| Key | Value |
| 145 | John |
| 147 | Bob |
| 160 | Julia |
Designing scope
- Support two operations:
- put(key, value) // insert “value” associated with the key
- get(key) // get “value” associated with the key
- The size of a key-value pair is small: less than 10KB
- Ability to store big data
- High availability: The system responds quickly, even during failures
- High scalability: The system can be scaled to support large data set
- Automatic scaling: The addition/deletion of servers should be automatic based on the traffic
- Tunable consistency
- Low latency
High-Level Design
First option: Single Server key-value Store
- Use a hash-table which keeps everything in memory.
- CONS:
- Memory Access is fast
- PROS:
- Fitting everything in memory may be impossible due to the space constraint
- Solutions:
- Data Compression
- Store only frequently used data in memory and the rest on the disk
This solution is not optimal since we can reach capacity very quickly.
Second Option: Distributed key-value Store
A distributed key-value store is also called a distributed hash table, which distributes key-value pairs across many servers.
There are two types:
- CP (consistency and partition tolerance) systems: a CP key-value store supports consistency and partition tolerance while sacrificing availability
- AP (availability and partition tolerance) systems: a AP key-value store supports availability and partition tolerance while sacrificing consistency
Main components of the Distributed key-value Store:
Data Partition
- For large applications, it is infeasible to fit the complete data set in a single server
- It is necessary to split the data into smaller partitions and store them in multiple servers
- There are two challenges when we partition the data:
- Distribute data across multiple servers evenly
- Minimize data movement when nodes are added or removed
- Consistent Hashing is a great technique to solve these issues.
- It allows to Automatic Scale: servers could be added and removed automatically depending on the load
- It allows Heterogeneity: the number of virtual nodes for a server is proportional to the server capacity
Data Replication
To achieve high availability and reliability, data must be replicated asynchronously over N servers, where N is a configurable parameter.
Nodes in the same data center often fail at the same time due to power outages, network issues, natural disasters, etc. For better reliability, replicas are placed in distinct data centers, and data centers are connected through high-speed networks.
Consistency
Since data is replicated at multiple nodes, it must be synchronized across replicas.
Quorum consensus can guarantee consistency for both read and write operations.
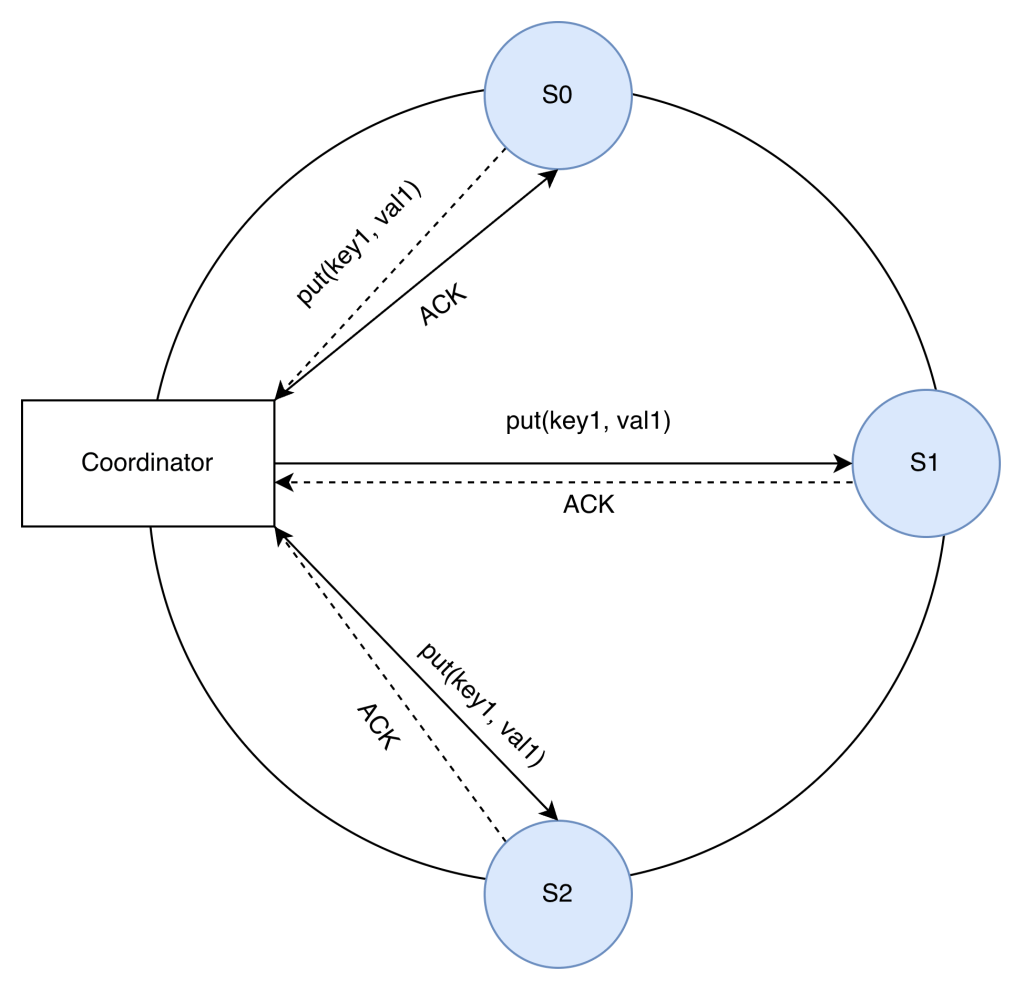
N = Number of replicas
W= A write quorum of size W. For a write operation to be considered as successful, write operation must be acknowledged from W replicas.
R = A read quorum of size R. For a read operation to be considered as successful, read operation must wait for responses from at least R replicas.
For the example above, N = 3.
If W = 1, it means that 1 server sent the acknowledge, and therefore, our coordinator considers the write operation successful. We don’t need to wait for the ACK from S1 and S2.
The configuration of W, R and N is a typical tradeoff between latency and consistency.
If R = 1 and W = N, the system is optimized for a fast read.
If W = 1 and R = N, the system is optimized for fast write.
If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
If W + R <= N, strong consistency is not guaranteed.
Depending on the requirement, we can tune the values of W, R, N to achieve the desired level of consistency.
Consistency Models
- Strong consistency: any read operation returns a value corresponding to the result of the most updated write data item. A client never sees out-of-date data.
- Strong consistency is usually achieved by forcing a replica not to accept new reads/writes until every replica has agreed on current write.
- This approach is not ideal for highly available systems because it could block new operations.
- Weak consistency: subsequent read operations may not see the most updated value.
- Eventual consistency: this is a specific form of weak consistency. Given enough time, all updates are propagated, and all replicas are consistent.
- Dynamo and Cassandra adopt eventual consistency, which is our recommended consistency model for our key-value store.
Inconsistency resolution: versioning
Replication gives high availability but causes inconsistencies among replicas.
To solve inconsistency problems, we can use:
- Versioning
- Treating each data modification as a new immutable version of data.
- Vector Clocks
- It is a pair [server, version] associated with a data item. It can be used to check if one version precedes, succeeds, or in conflict with others.
Handling Failures
These are common failure resolution strategies
Failure Detection
In a distributed system, it is insufficient to believe that a server is down because another server says so. Usually, it requires at least two independent sources of information to mark a server down.
A method for failure detection is the Gossip Protocol.
Basically, each server has a membership list where it stores other members and its heartbeats. Each server increments its heartbeat counter. Each server sends its counter to random servers so they can update their membership list. If a heartbeat has not increased for more than predefined periods, the member is considered as offline. Other members also confirm this, and the server is marked down.
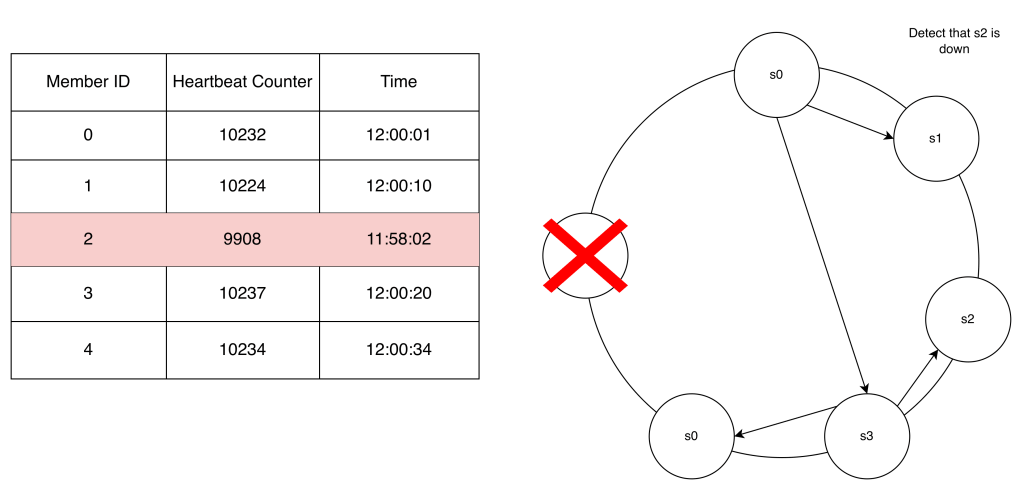
Handle Temporary Failures
After failures have been detected, we need to deploy certain mechanisms to ensure availability.
- Strict Quorum Approach: read and writes could be blocked
- Sloppy Quorum Approach: Used to improve availability. Instead of enforcing the quorum requirement , the system chooses the first W healthy servers for writes and first R healthy servers for reads on the hash ring. Offiline servers are ignore.
- Hinted handoff: when a server is off, reads and writes are handled by another server. Once the failed server is up, the “covered” server will handle the data back.
Handle Permanent Failures
What if a server will never be up again?
We can use the Anti-Entropy Protocol to keep replicas in sync.
Anti-entropy involves comparing each piece of data on replicas and updating each replica to the newest version.
A Merkle tree is used for inconsistency detection and minimizing the amount of data transferred. Basically, you build a Merkle tree (hash tree) and compare that the roots match, if they don’t match, then there is inconsistency. You can traverse the tree to find which buckets are not synchronized and synchronize those buckets only.
Handle data center outage
To build a system capable of handling data center outage, it is important to replicate data across multiple data centers. Even if a data center is completely offline, users can still access data through the other data centers.
System Architecture Diagram
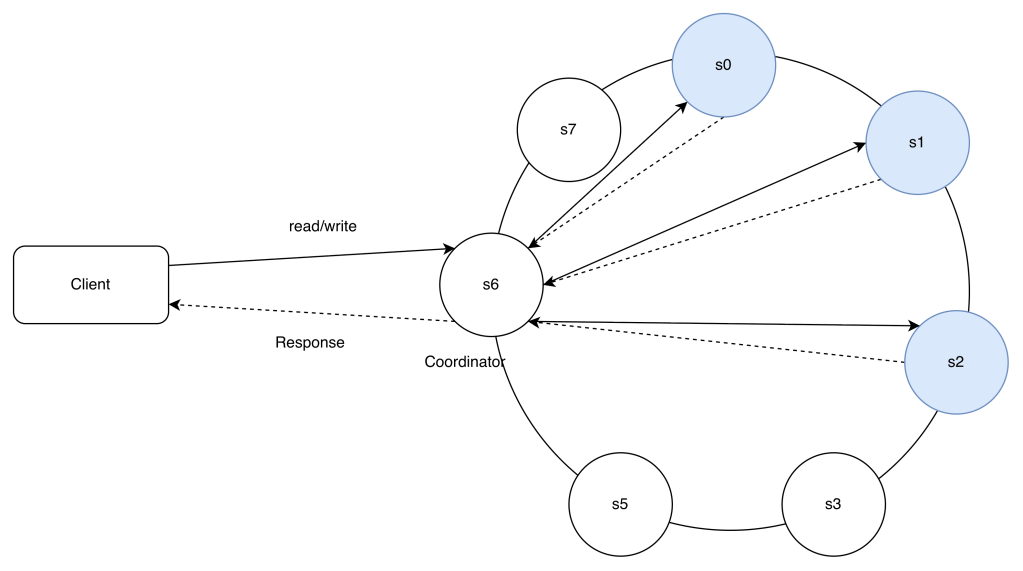
- Clients communicate with the key-value store through simple APIs: get(key) and put(key, value).
- A coordinator is a node that acts as a proxy between the client and the key-value store.
- Nodes are distributed on a ring using consistent hashing.
- The system is completely decentralized so adding and moving nodes can be automatic.
- Data is replicated at multiple nodes.
- There is no single point of failure as every node has the same set of responsibilities
Write Operation
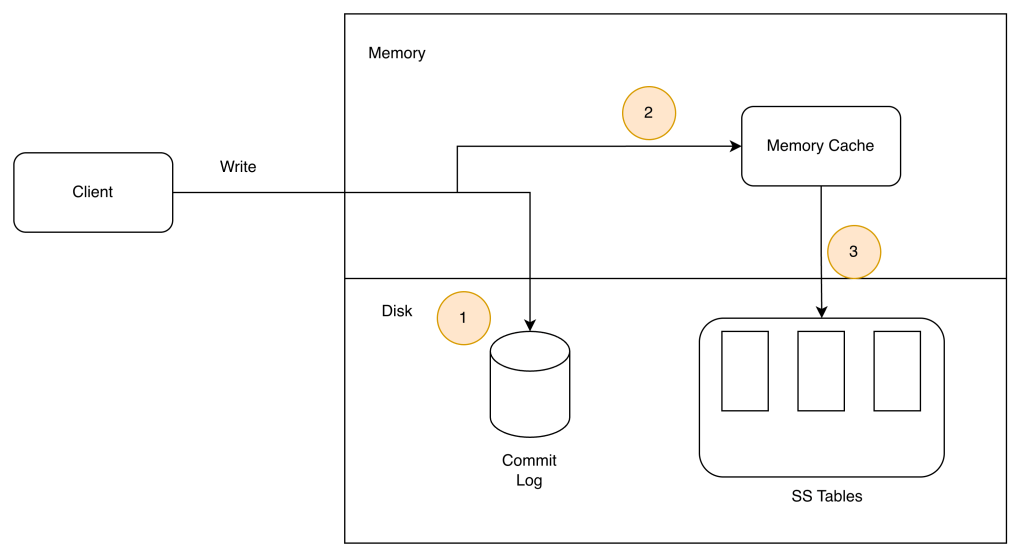
1. The write request is persisted on a commit log file.
2. Data is saved in the memory cache.
3. When the memory cache is full or reaches a predefined threshold, data is flushed to SSTable
- sorted-string table (SSTable) is a sorted list of <key, value> pairs.
Read Operation
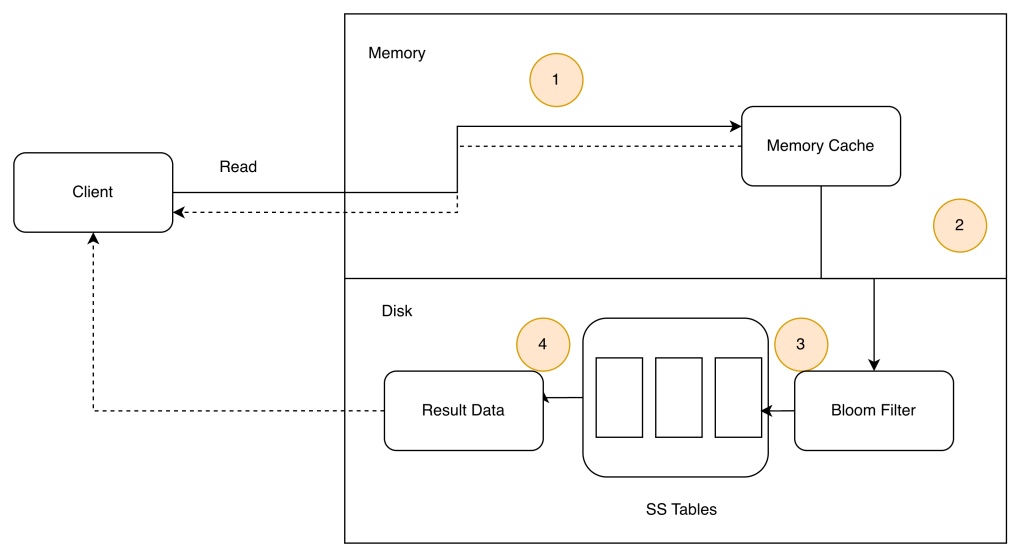
- The system first checks if data is in memory. If not, go to step 2. If so, return data
- If data is not in memory, the system checks the bloom filter.
- The bloom filter is used to figure out which SSTables might contain the key.
- SSTables return the result of the data set.
- The result of the data set is returned to the client.
