To achieve horizontal scaling, it is important to distribute requests/data efficiently and evenly accros servers. Consistent hashing is a commonly used technique to achieve this goal.
The problem
If you have n cache servers, a common way to balance the load is to use the following hash method:
where N is the size of the servel pool
Example:
We have 4 servers and 8 string keys with their hashes
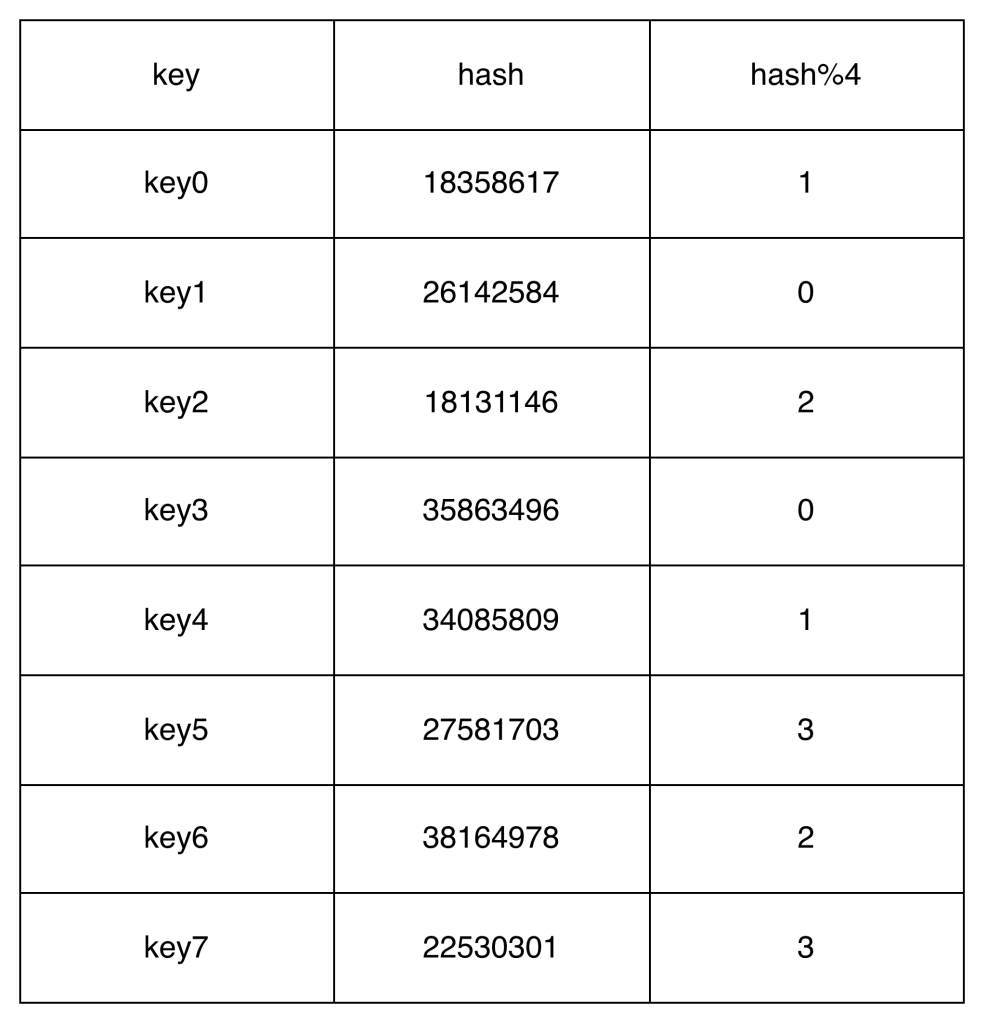
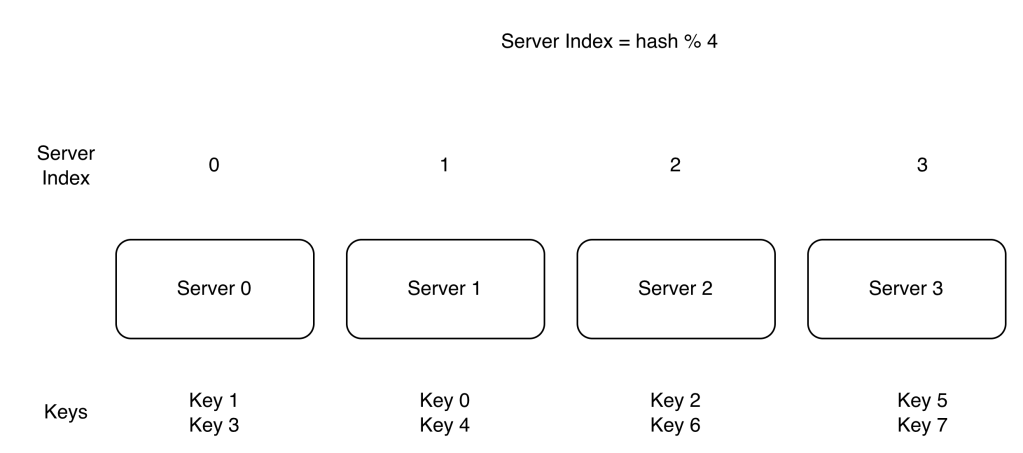
To select the server where our request should go, we do hash(key0) % 4 = 1. This means that the client must contact server 1 to fetch the cached data.
This approach works well when the size of the server pool is fixed, and data distribution is even. However, problems arise when new servers are added or existing servers are removed.
To solve this issue of traditional hashing, we use Consistent Hashing:
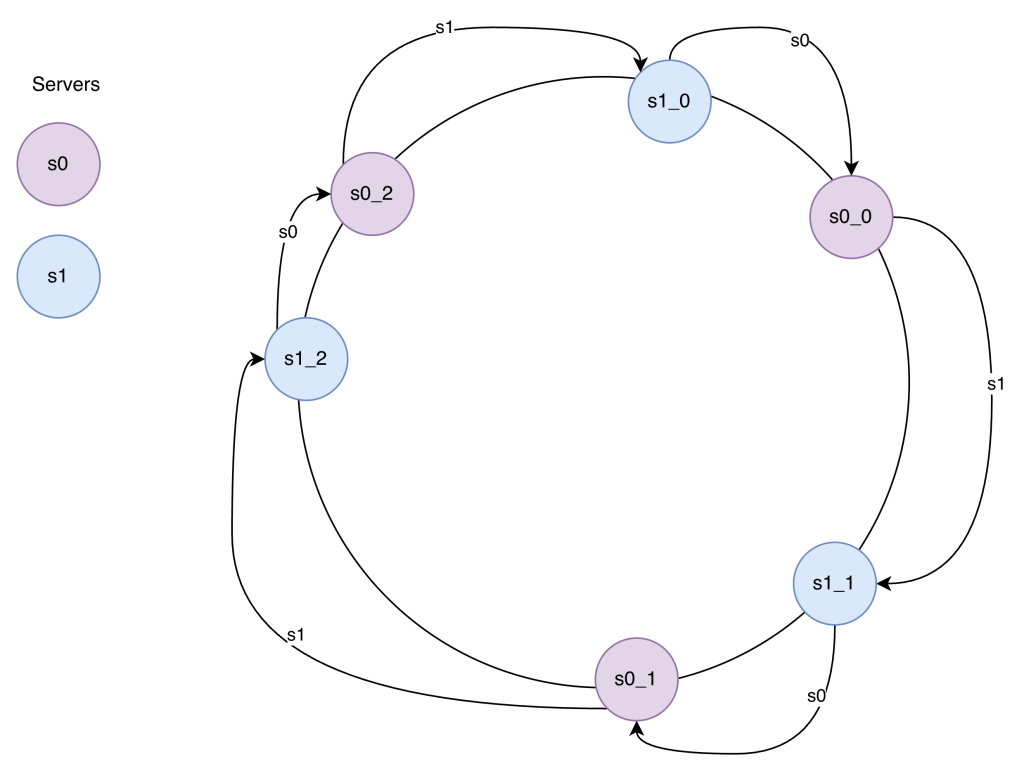
Consistent Hashing: When you change the number of servers (or slots), only k/n keys move instead of almost all keys moving.
On average, only about 1/n of all keys need to be reassigned when something changes.
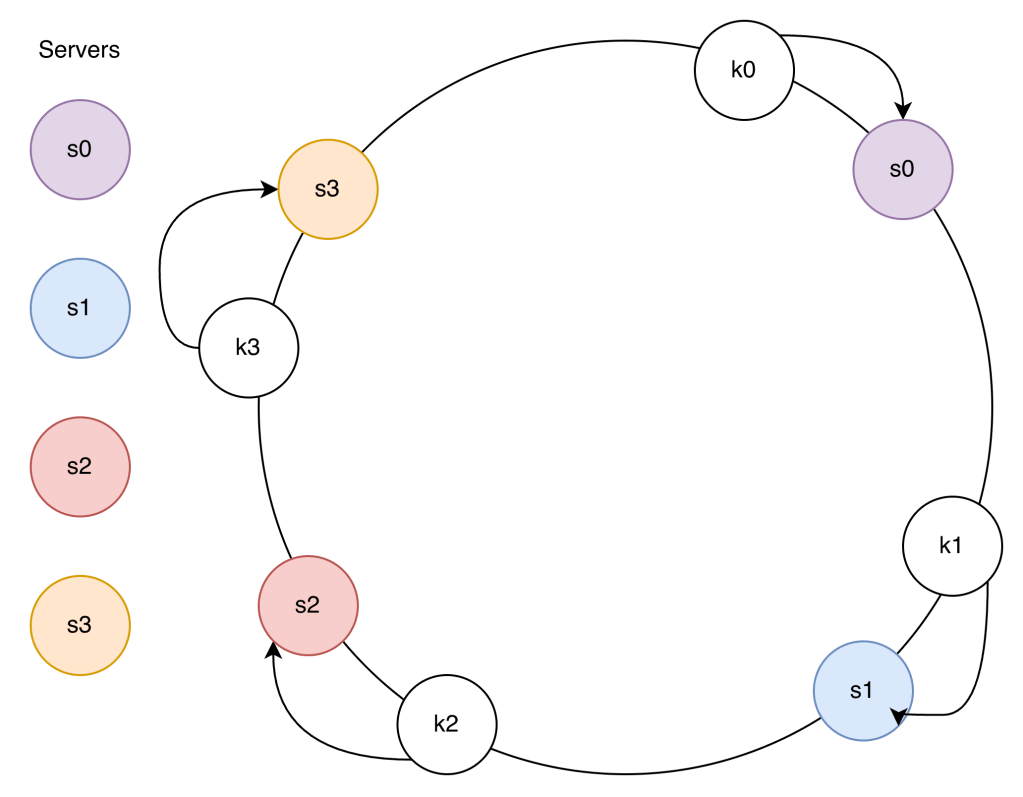
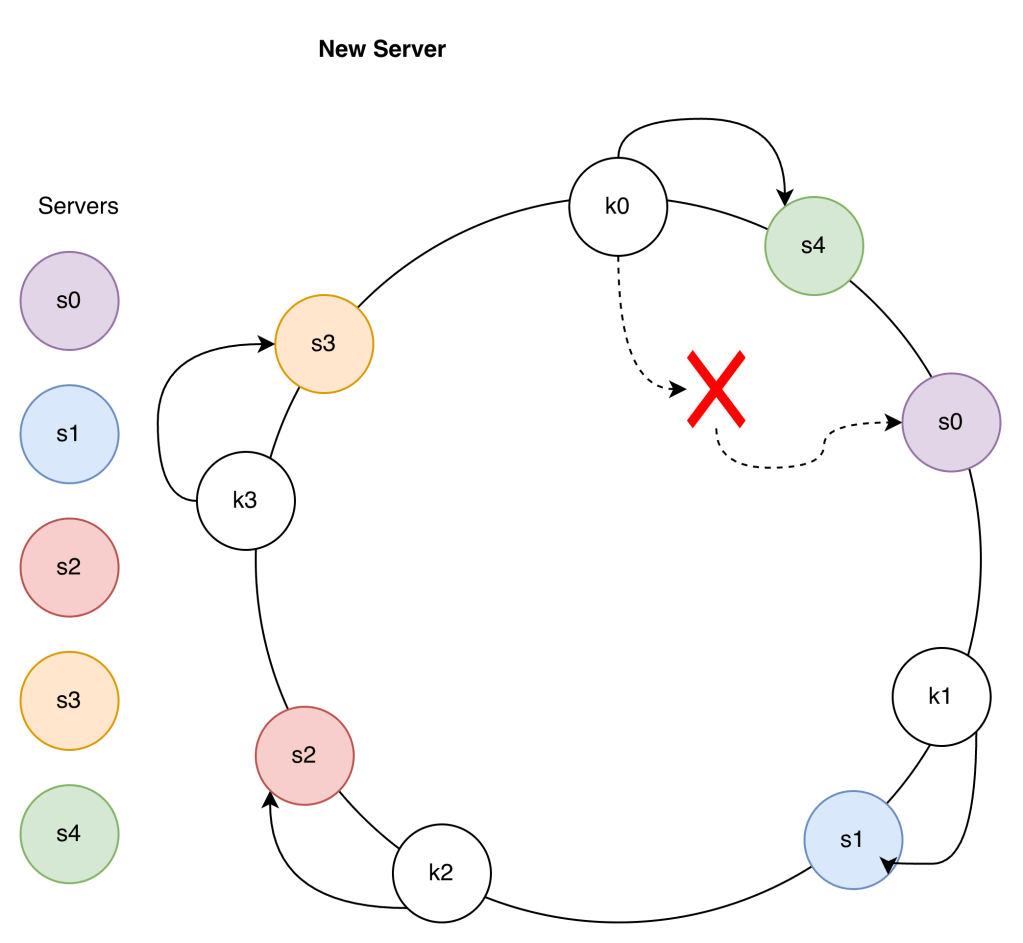
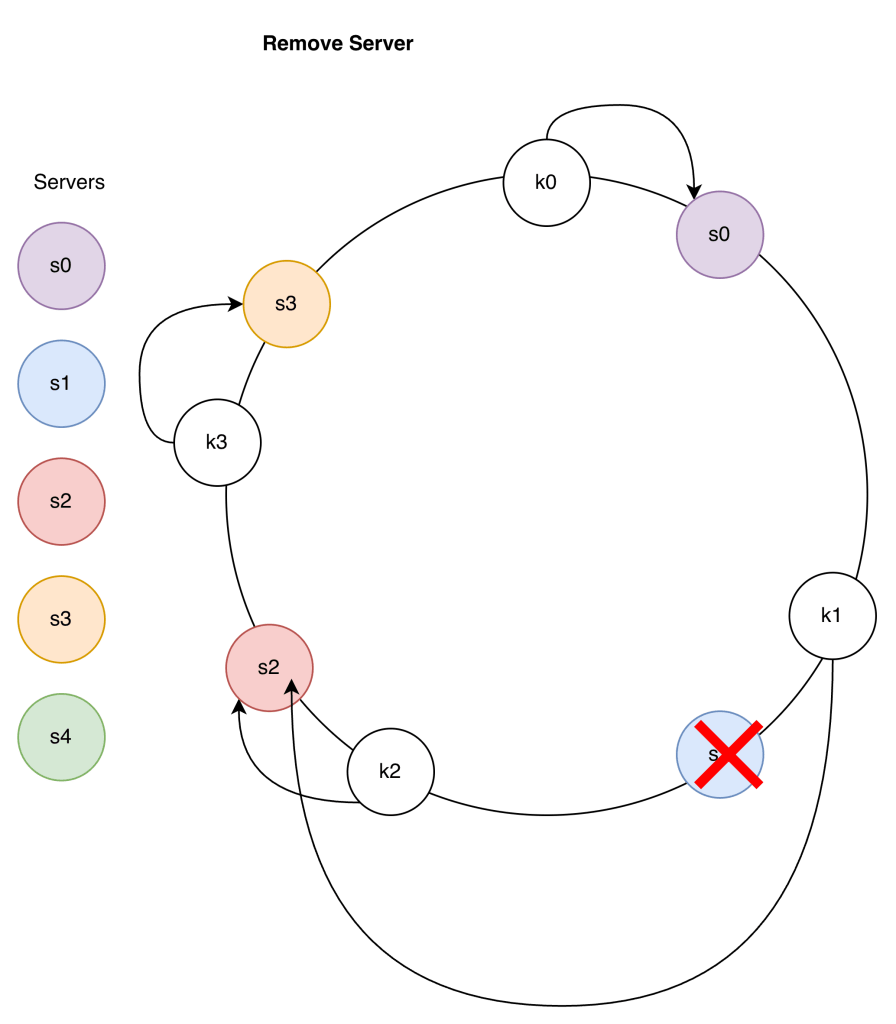
Two problems with this approach:
- The space between servers is not uniform if a Server is added or removed
- It is possible to have a non-uniform key distribution on the ring
To solve this, we can use:
Virtual Nodes: A virtual node refers to the real node, and each server is represented by multiple virtual nodes on the ring
As the number of virtual nodes increases, the distribution of keys become more balanced. This is because the standard deviation gets smaller with more virtual nodes, leading to balanced data distribution. The trade-off: more nodes = more space needed to store data for those virtual nodes